
🆘 Flooding Rescue Voice Assistant - Personal Diary
Course: COMP4461 Human-Computer Interaction
Project: Project 2 - Flooding Rescue Voice Assistant
Role: Full-stack Developer & Chat Agent Designer
—
📋 Project Overview
This project is a Flooding Rescue Voice Assistant designed to help emergency dispatchers efficiently collect critical information from flood victims while providing real-time guidance and emotional support. The system integrates Automatic Speech Recognition (ASR), Large Language Models (LLM), and Text-to-Speech (TTS) technologies to create a natural, conversational voice interface.
Key Features:
- 🎤 Real-time voice recognition and transcription
- 🤖 Intelligent conversation management with context awareness
- 🔊 Natural voice synthesis for system responses
- 📊 Automatic information extraction and prioritization
- 🚨 Dynamic urgency status assessment
- 🗺️ ETA calculation and safe location recommendations
🎯 My Contributions
1. Complete Chat Agent Architecture Design (100% ownership)
I was responsible for the entire conversational AI system design, from the initial concept to the final implementation. This included:
- System architecture design: Designing the multi-layered conversation flow
- Prompt engineering: Crafting effective system prompts for different scenarios
- Information extraction logic: Implementing intelligent data parsing from natural language
- State management: Building a robust session management system
- Error handling: Ensuring graceful degradation when components fail
2. Frontend-Backend Integration (100% ownership)
I integrated the frontend user interface with the backend AI services, including:
- WebSocket implementation for real-time audio streaming
- REST API design for message handling and status updates
- CORS configuration for cross-origin requests
- SSL certificate generation for secure HTTPS connections
- Audio file management for TTS output delivery
🔄 Chat Agent Design: The Iteration Journey
Version 1.0: Basic Streamlit Interface (chat.py)
Design Philosophy: Start simple with a GUI-based prototype
Key Features:
# Initial approach: Direct streaming TTS
def voice_chat_worker(config, stop_event):
# Simple conversation loop
while not stop_event.is_set():
text = asr.get_result()
if text:
response = llm.chat(text)
tts.streaming_synthesize(response)
User Need Consideration:
- Visual feedback: Users need to see their conversation history
- Control interface: Simple START/STOP buttons for easy operation
- Status indicators: Real-time priority score and information collection status
Challenges Identified:
- ❌ Rigid conversation flow: No context awareness between turns
- ❌ Redundant questions: System repeatedly asks for already-provided information
- ❌ Limited scalability: Single-session only, no multi-user support
Version 2.0: Intelligent Context Management (chat.py - Enhanced)
Design Evolution: Add memory and context tracking
Key Improvements:
def extract_rescue_info(text: str) -> Dict[str, Any]:
"""Extract rescue-related information from user text."""
# Comprehensive keyword matching for:
# - Number of people (with "alone" detection)
# - Injury status (with negation handling)
# - Water level indicators
# - Vulnerable populations
# - Available resources
User Need Consideration:
- Avoid repetition: Track what information has been collected
- Smart inference: If user says “I’m alone”, infer num_people = 1
- Negative detection: Understand “no one injured” vs “someone injured”
Example:
# Before: Dumb extraction
if "injured" in text:
info["has_injury"] = True # Wrong if user says "no one injured"
# After: Smart extraction with negation handling
no_injury_patterns = [
"no one injured", "not injured", "we're fine", "not hurt"
]
if any(pattern in text_lower for pattern in no_injury_patterns):
info["has_injury"] = False # ✅ Correctly handles negation
elif any(keyword in text_lower for keyword in injury_keywords):
info["has_injury"] = True
Challenges Identified:
- ❌ Pattern matching limitations: Can’t handle complex linguistic variations
- ❌ No web access: Limited to localhost
- ❌ Missing frontend separation: Hard to customize UI
Version 3.0: LLM-Powered Conversation (final_version_with_frontend.py)
Design Revolution: Replace rule-based logic with LLM intelligence
Architectural Shift:
def get_llm_rescue_response(user_text: str) -> Dict[str, Any]:
"""Use LLM to handle conversation and information extraction"""
# Build conversation history
messages = [{"role": "system", "content": system_prompt}]
recent_history = session.conversation_history[-10:] # Keep context
for msg in recent_history:
messages.append(msg)
# Let LLM maintain conversation naturally
response = llm.generate_from_messages(messages)
System Prompt Engineering:
system_prompt = """You are a professional flood rescue assistant.
CONVERSATION STYLE:
- Ask ONLY 1-2 questions at a time, like a real person would
- Keep your response brief (2-3 sentences maximum)
- Wait for the user's answer before asking the next question
INFORMATION TO GATHER (ask separately, ONE topic at a time):
1. Number of people
2. Injuries
3. Water level
4. Location safety
IMPORTANT RULES:
- NEVER ask multiple questions in one response
- Remember what the user already told you
- If user says "I'm alone", don't ask about children/elderly
"""
User Need Consideration:
- Natural conversation: LLM creates human-like dialogue flow
- Context retention: System remembers previous answers
- Adaptive questioning: Adjusts questions based on user’s situation
- Emotional intelligence: Balances information gathering with empathy
Separate Information Analysis:
def analyze_people_and_urgency(conversation_history):
"""Use independent LLM instance for background analysis"""
analysis_prompt = f"""Extract from conversation:
1. Number of adults
2. Number of children
3. Number of elderly
4. Urgency status: LESS URGENT / URGENT / EMERGENT
RULES:
- If already known (not N/A), KEEP IT unless user corrects
- Only update N/A values when new information found
- Return 0 (not N/A) when user explicitly states none
"""
# Create separate LLM to avoid polluting main conversation
analysis_llm = create_llm(model="qwen-plus")
response = analysis_llm.chat(analysis_prompt)
Why Separate LLM Instance?
- 🎯 Clean separation: Analysis doesn’t interfere with conversation
- 🎯 Incremental updates: Only update when new information appears
- 🎯 Avoid confusion: Main conversation LLM stays focused on user
Example Interaction:
User: "Yes, I need help"
Assistant: "Copy that. How many adults are with you?"
User: "5 adults"
Assistant: "Understood, 5 adults. Are there any children or elderly with you?"
User: "Yes, 1 child"
Assistant: "Got it, 1 child. Any elderly people?"
User: "No elderly"
Assistant: "Copy that. Is anyone injured or in immediate danger?"
Challenges Identified:
- ❌ Information drift: LLM sometimes “forgets” confirmed numbers
- ❌ Over-asking: Still asks about children/elderly even when user said “I’m alone”
Version 4.0: Staged Information Collection (flooding_rescue_api_version.py)
Design Refinement: Implement explicit conversation stages
Staged Collection Logic:
class RescueSession:
def __init__(self):
# Stage tracking flags
self.adult_count_asked = False
self.adult_count_confirmed = False
self.children_elderly_asked = False
self.children_elderly_confirmed = False
self.info_confirmed = False # Stop asking when complete
Stage 1: Adult Count
if not session.adult_count_confirmed:
analysis_prompt = """Extract ONLY the number of ADULTS.
RULES:
- If user says "I'm alone": return ADULT=1
- If mentions specific number: return that number
- If says "we" without number: return N/A
Respond: ADULT: [number or N/A]
"""
# Once confirmed, move to Stage 2
if adult_count == 1:
# Special case: If alone, auto-set children=0, elderly=0
session.children_elderly_confirmed = True
Stage 2: Children and Elderly
if adult_count_confirmed and not children_elderly_confirmed:
analysis_prompt = """Extract CHILDREN and ELDERLY.
CRITICAL RULES:
- If mentions children but NOT elderly: CHILDREN=[n], ELDERLY=0
- If mentions elderly but NOT children: ELDERLY=[n], CHILDREN=0
- If says "no children": CHILDREN=0
- Return N/A only if not mentioned at all
"""
User Need Consideration:
- Efficiency: Stop analyzing once information is complete
- Intelligence: Infer implicit information (alone → no children/elderly)
- Consistency: Lock confirmed values to prevent drift
- Performance: Skip unnecessary LLM calls with
info_confirmedflag
Optimization:
def analyze_people_and_urgency(conversation_history):
# STOP unnecessary processing
if session.info_confirmed:
print("✅ All information confirmed, skipping LLM analysis")
return current_info
# Stage-based analysis
if not session.adult_count_confirmed:
# Only analyze adults
elif not session.children_elderly_confirmed:
# Only analyze children/elderly
else:
# Only update urgency status
Version 5.0: Frontend-Backend Separation (Final Version)
Architectural Components:
- Backend (FastAPI):
- WebSocket for real-time audio streaming
- REST API for message handling
- Session management
- AI model orchestration
- Frontend (HTML/CSS/JavaScript):
- Modern responsive UI
- Web Audio API for microphone access
- Real-time transcription display
- Status panels and visualizations
Integration Points:
# Backend WebSocket endpoint
@app.websocket("/ws/audio")
async def websocket_audio_endpoint(websocket: WebSocket):
await websocket.accept()
# Create ASR instance for this connection
local_asr = create_asr(model="paraformer-realtime-v2")
local_asr.start()
while not ws_closed:
audio_data = await websocket.receive()
local_asr.recognition.send_audio_frame(audio_data["bytes"])
text = local_asr.get_result()
if text:
await websocket.send_json({
"type": "transcript",
"text": text
})
// Frontend: Connect to WebSocket
const ws = new WebSocket('wss://localhost:8000/ws/audio');
// Send audio stream
navigator.mediaDevices.getUserMedia({ audio: true })
.then(stream => {
const audioContext = new AudioContext();
const processor = audioContext.createScriptProcessor(4096, 1, 1);
processor.onaudioprocess = (e) => {
const audioData = e.inputBuffer.getChannelData(0);
ws.send(audioData); // Send to backend
};
});
// Receive transcriptions
ws.onmessage = (event) => {
const data = JSON.parse(event.data);
if (data.type === 'transcript') {
displayTranscription(data.text);
}
};
User Need Consideration:
- Accessibility: Works on any device with a browser
- Real-time feedback: Instant transcription display
- Visual clarity: Separate panels for conversation, status, and actions
- Network resilience: Handles disconnections gracefully
🖼️ Frontend User Interface
Main Interface Screenshot
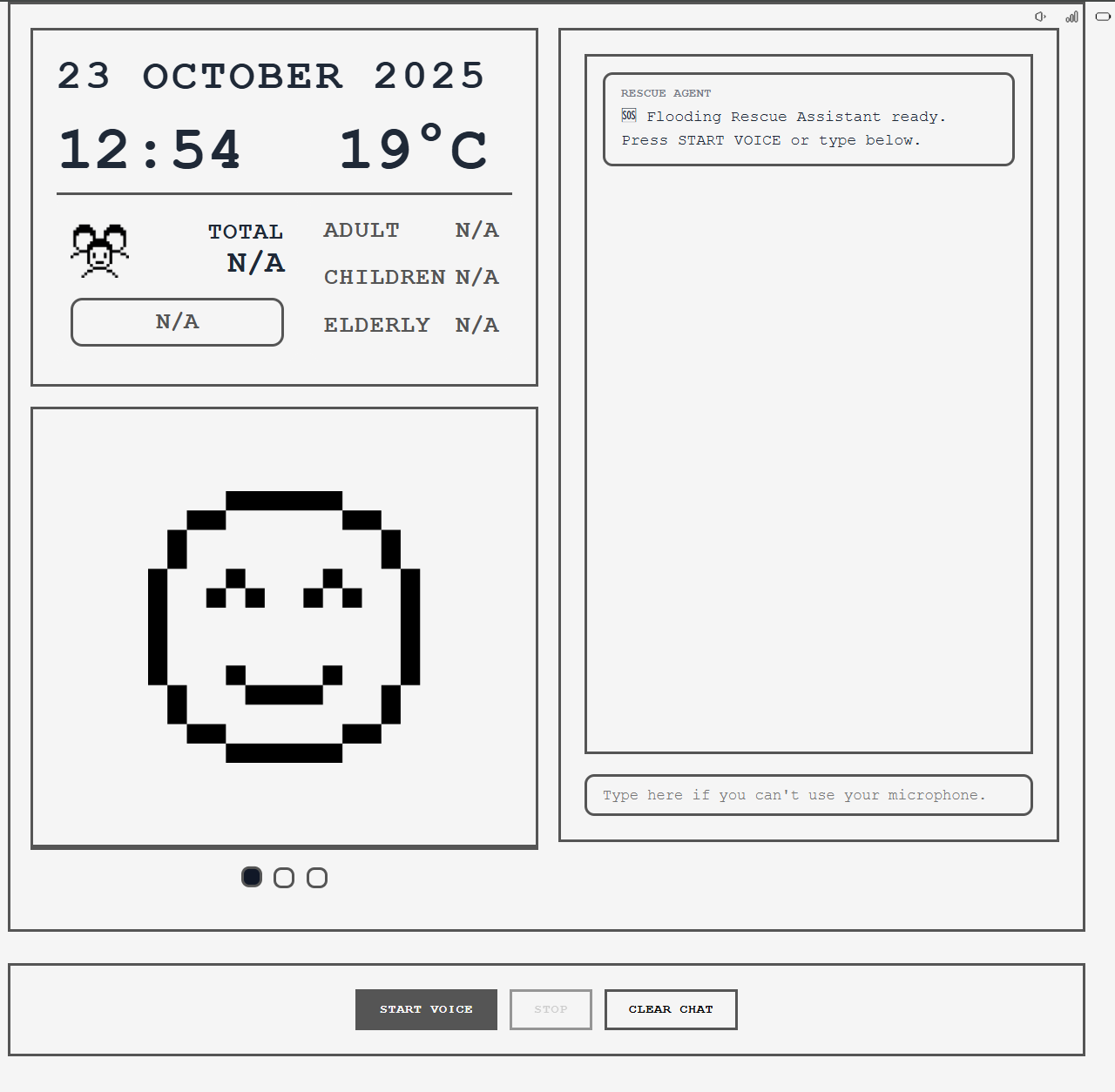
Key UI Components
- Conversation Area:
- Real-time message display
- User and assistant messages clearly distinguished
- Auto-scroll to latest message
- Status Panel:
- People count (Adults / Children / Elderly / Total)
- Urgency status indicator (LESS URGENT / URGENT / EMERGENT)
- Information collection progress
- Control Panel:
- Microphone toggle button
- Volume indicator
- Connection status
- Guidance Panel:
- Safety tips
- Nearby safe locations
- ETA information (when available)
🤖 AI Usage Acknowledgment
AI Tools Used
- Claude AI (Anthropic) - Used for:
- Code debugging and optimization suggestions
- Documentation writing assistance
- System prompt refinement ideas
- LLM APIs - Integrated into the system:
- Qwen-Plus (Alibaba): Main conversation LLM
- Paraformer (Alibaba): Real-time ASR
- CosyVoice (Alibaba): Text-to-speech synthesis
Human Contributions
All core design decisions, architecture, and implementation were done by me:
- ✅ System architecture and conversation flow design
- ✅ State management and session handling logic
- ✅ All prompt engineering and testing
- ✅ Frontend-backend integration
- ✅ All code implementation and debugging
- ✅ User testing and iteration based on feedback
AI was used only as a coding assistant, not as the primary designer or implementer.
💭 Reflection and Learnings
What Went Well
- Iterative Design Approach:
- Each version addressed specific shortcomings of the previous one
- Gradual complexity increase prevented overwhelm
- Regular testing at each stage ensured stability
- User-Centered Thinking:
- Considered different user scenarios (alone vs. with family, injured vs. safe)
- Designed for high-stress situations (brevity, clarity, reassurance)
- Balanced information gathering with emotional support
- Technical Integration:
- Successfully integrated multiple AI services (ASR, LLM, TTS)
- Achieved real-time performance with WebSocket streaming
- Handled edge cases and error states gracefully
Challenges Faced
- LLM Hallucination:
- Problem: LLM sometimes “made up” information not stated by user
- Solution: Separate analysis LLM with strict extraction rules
- Lesson: Don’t trust LLM memory; use explicit state management
- Context Window Limits:
- Problem: Long conversations exceeded LLM context limits
- Solution: Keep only recent 10 messages in conversation history
- Lesson: Design for realistic conversation lengths
- Information Consistency:
- Problem: LLM changed confirmed values in later analysis
- Solution: Lock confirmed values with flags (
adult_count_confirmed) - Lesson: Human-like memory requires explicit tracking, not just prompts
- Network Latency:
- Problem: TTS generation delay created awkward pauses
- Solution: Use streaming synthesis and audio buffering
- Lesson: Real-time systems need careful latency management
What I Would Do Differently
- Earlier User Testing:
- I focused too much on technical implementation early on
- Should have tested with real users after Version 2.0 to identify usability issues
- More Structured State Machine:
- The staged collection approach came late in the project
- A formal state machine design from the start would have saved iteration time
- Better Error Messages:
- Current error handling is functional but not user-friendly
- Would add more specific, actionable error messages for users
- Conversation Repair Strategies:
- Need better handling when LLM misunderstands user input
- Should implement confirmation questions for critical information
Future Improvements
- Offline Mode: Cache essential functionality for no-internet scenarios
- Visual Aids: Add map integration to show rescue team location
- Database Integration: Store conversations for analysis and improvement
- Multi-User Dashboard: Allow dispatchers to manage multiple rescue calls